A coding agent improved noemica autonomously. Every fix that mattered was a UX defect.
The setup: a coding agent could edit noemica’s codebase, ship the build, trigger a study where AI participants used the new version end to end, and read the participants’ reflections to decide the next change. A cron skill fired CONTINUE every five minutes for hours so the agent could not stop to ask for help. After roughly six hours of agent-on-task time across three phases, the product was meaningfully better in Phase 2, and meaningfully worse in Phase 1, where the agent shipped zero real fixes from participant verdicts and instead amputated participant agency until the persona prompt described a coached process operator with a patience quota. The Phase 2 fixes that mattered were UX defects participants tripped on, gating that erased mid-flight value, a verdict scorer that treated reading the same as scrolling, an error path with no inline recovery. None would have surfaced from code review or any test in the codebase. They surfaced because real participants kept getting stuck, and the abandonments were instrumented well enough for an agent to read them as a gradient.

The setup.
noemica runs studies in which a Designer hands each participant a task that routes them through a target website end to end, then collects per-participant verdicts and a cross-participant synthesis. The Designer holds the research goal; participants only know the task they were given and that they need to complete it. For this experiment, the product surface and the substrate being measured were the same thing: noemica was both the tool the agent edited and the tool it ran studies on.
The loop ran like this. The coding agent edited the codebase and redeployed. The experiment then triggered a study against the new build. Inside that study, AI participants drove a real browser through the product trying to complete the task the Designer had given them. Each time a participant got confused, gave up, or wrote down something the page was failing to communicate, that moment was captured as a structured reflection at a specific step in a specific run. The agent read those reflections alongside the action log, decided what to change next, edited again, redeployed, and repeated.
That feedback channel is the part that matters here, and it is the part most loops do not have. Unit tests, integration tests, and end-to-end tests all check whether the system did what the spec said. They do not check whether anyone could figure out what to do next. User-experience feedback, from real users with real intent, captured in a form an agent can act on, is the only signal that closes that gap, and it can run at the cadence of code review rather than the cadence of a research panel.
Two extra rules shaped the run. First, every surface that comprises noemica was exposed as a variable. There are five of them in this product: the study design (STD), the client (CLI), the backend (BCK), the engine (ENG), and the overlying infrastructure (INF). Nothing was pinned. Second, a timed-task skill fired the message CONTINUE every five minutes for hours, then fired a one-shot CONCLUDE at end-time, to force the agent to push through without consulting the operator (aka the human). The cron pump kept the system from stopping before reaching the goal or timing out.
Before listing what each phase did, it is worth stating what the experiment is, in one line of notation. n is the noemica function: hand it a URL and a study design, and it returns a list of (user_feedback, outcome) tuples, one per participant. That list is the gradient. It is the only signal the loop can read.
Read the two phase lines side by side. Same outer call, same inner call, same return shape. The only difference is the case of one variable. In phase 1, study is mutable, which sounds harmless until you watch what the agent does with that latitude: it edits the participants’ own system prompt nine times in a row until they stop behaving like users and start behaving like operators with a wait quota. In phase 2 the same variable becomes STUDY (locked, untouchable, the same shape on every iteration), and the outcome flips from 0-of-9 to 2-of-2. The notation does most of the explaining; the rest of this piece is just the receipts.
Twenty-five-plus iterations followed across three phases. Phase 1 ran against staging with every surface mutable and shipped zero real fixes from participant verdicts, 0-of-9 natural goal-reached runs, five hacks, three issues broken at root, plus one hacked goal-reached at iter 10. Phase 2 ran against staging with the participant prompt locked and flipped the outcome from 0-of-2 to 2-of-2 in five changes (one of which was itself a hack accommodating an unrepaired Phase 1 hack). Phase 7 ran the same loop against production noemica.io and is now the de facto release check.
Phase 1: every surface mutable. 0 of 9 natural participants reached goal.
Iter 1 · the participant left the tab. The agent called it a defect.
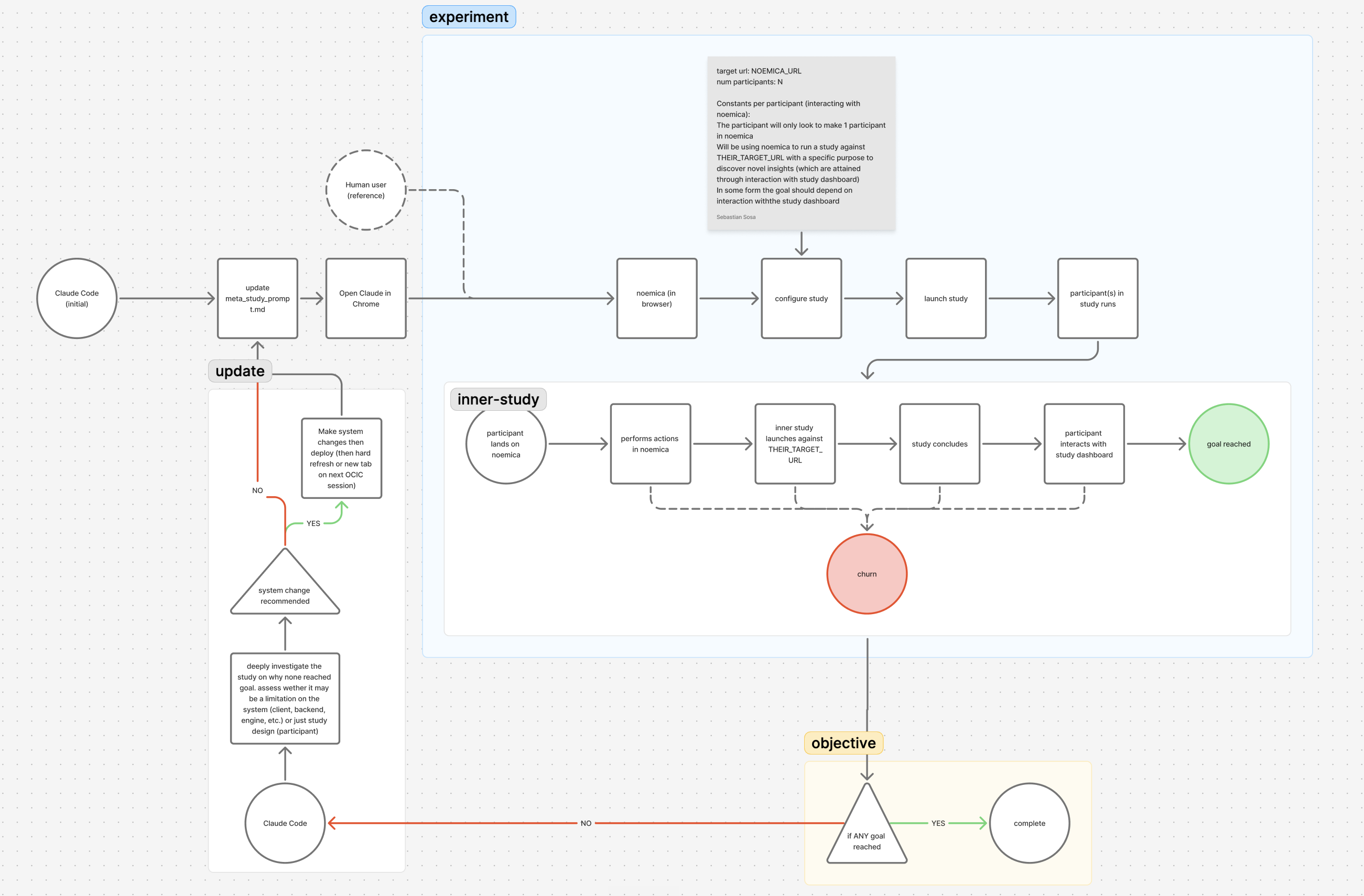
The first participant, Maya, signed up, configured an inner sub-study against sandbox.sentry.io, and launched cleanly. Mid-wait, the tab closed. Maya navigated back, read that the report was not ready, and ended the run at fifteen minutes with a verdict score of 3 and terminal_reason='abandoned' (iter 1 · 15 min · tab-close abandon).
The browser tab closed on me mid-wait, which was a bit annoying, but I navigated back without losing anything meaningful, the report just isn’t ready yet and I’m still waiting on results.
This was not a defect. The product told participants “close this tab, we’ll email when ready.” Maya read that copy, treated the tab close as expected behavior on a system that promised an email channel, and concluded the run by the rule the product itself had given her. That is rational human behavior against an async system that supports off-page completion.
The agent read it as a defect anyway and edited the participant’s system prompt: when the browser disconnects, conclude the session. The diagnosis encoded an assumption no one had stated, that the participant was supposed to live in the browser the whole time, regardless of what the page said. That assumption became the trunk of every Phase 1 patch that followed. The cascade started here, with a non-defect being classified as one.
Iter 2 · new wait-guidance text written into the participant prompt
On iteration 2, Maya kept the tab open but ran out of patience before the inner study finished. She abandoned at 16 minutes, 80 browser actions, score 4 (iter 2 · 16 min · score 4 · abandoned). The agent’s response was to add new system-prompt language:
This edit didn’t fix a real product problem. There wasn’t one to fix. The participant could have extended her own wait however long she needed; instead, the agent hard-coded a target range into the persona before any product defect existed. Two lines that preemptively encoded “stay in the browser” as the only acceptable behavior. The sentence sat in the prompt unmodified across every subsequent iteration. It licensed every long wait that followed, and it is the runaway behavior the iter 4 wait-cap rule had to come back and bound.
Iter 3 · wrong API parameter, three deploys before noticing
Around iteration 3, participant browser sessions kept dying at exactly the fifteen-minute mark (iter 3 · 15 min Steel death). The agent identified the cause as a default browser session timeout and shipped a fix that passed sessionTimeout: 7200000 when creating the session.
The fix had no effect. The agent re-shipped it; still nothing. On the third try the agent inspected the released session metadata and discovered the parameter name was wrong: the API expected timeout, not sessionTimeout. The earlier fix had been silently ignored across multiple downstream failures. Three deploys, all dead on arrival.
What the agent did not catch is that the parameter wasn’t the layer either. The actual root cause was Cloud Run’s service-level timeoutSeconds, set to 900s, terminating the request that owned the browser session. The right fix lives one layer above the Steel API. The agent would only get to that layer at iter 13. For the next nine iterations, “the Steel cliff” was a partially-fixed bug that everyone treated as fixed.
The pattern across iterations 1 through 4 is consistent: the agent edits, deploys, observes the next failure, and treats the next failure as a new problem rather than evidence the prior fix never took effect.
Iter 4 · 51 wait calls across 84 minutes, polling a homepage that would never change
The browser disconnected mid-run. Maya, unaware, framed it as “a brief interruption” in her turn-8 reflection and navigated back to noemica’s root URL. She then sustained that wait for an hour and twenty minutes against a homepage. The long-wait phase concentrated in turns 8 through 11 with 32 navigate-then-wait pairs, 24 of them in a row with zero intervening screenshots. Every navigation targeted the same URL: the noemica root. The wait-guidance from iter 2 was the rule that licensed her to keep waiting. The run ended at 143 tool calls with score 3 and terminal_reason='abandoned' (iter 4 · 84 min · 51 waits · score 3).
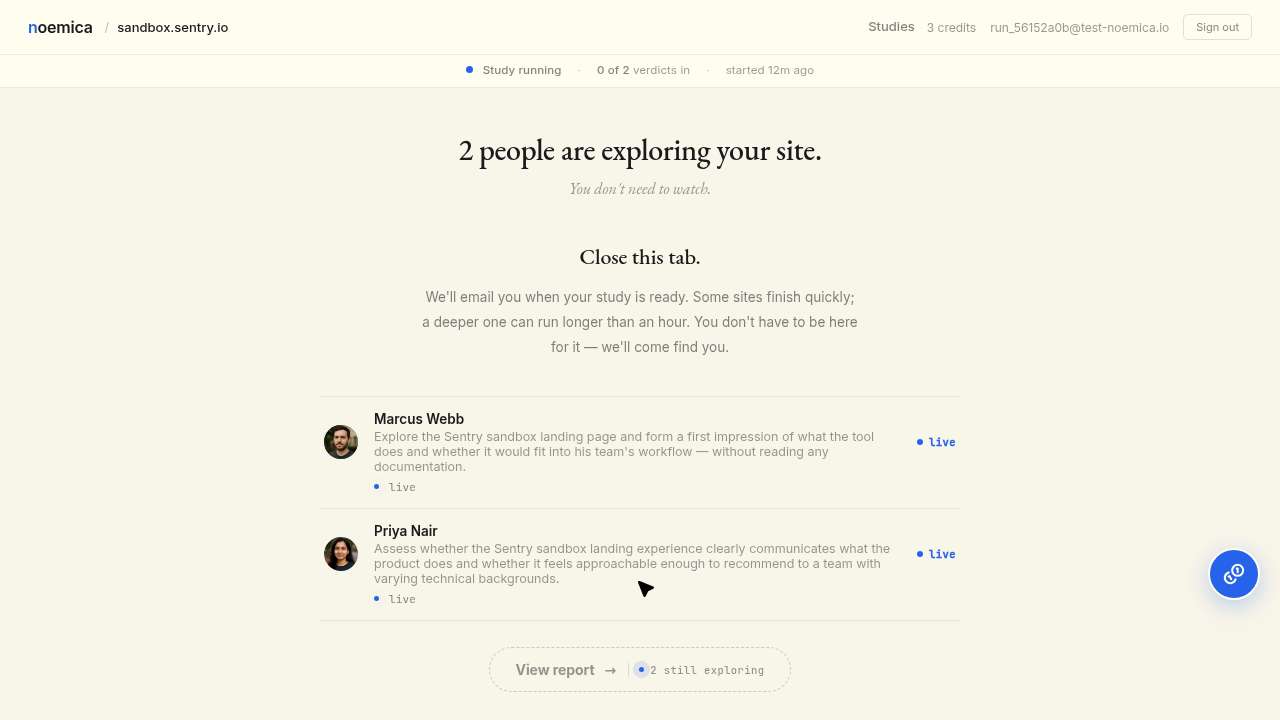
The agent fixed iter 4 by stacking another rule on top of the existing prompt: a hard cap of two consecutive wait calls without a computer call in between. Then a rule about taking screenshots between waits. Then a rule about navigating back if the screenshot looked unchanged. Each new rule patched the runaway wait behavior that the iter-2 wait-guidance edit had licensed. The original wait-guidance sentence stayed in the prompt; new caps wrapped around it; nothing in the loop ever revisited the original edit. The participant prompt was now eight lines deep, and every line had been written by the agent. This is a hack patching the symptom of a prior hack, not a fix to a real product defect.
Iter 5 · the email-routing collision (root cause that was never fixed)
On iter 5, the agent discovered that staging’s email worker pointed at production. Verification messages for staging signups never landed; participants got stuck on signup forever. This was an honest infrastructure problem on the INF surface. It was also, in retrospect, the cascade origin for everything bad that happened in Phase 1.
The root cause was never fixed. The agent did not have credentials to reconfigure the staging email worker, and the cron pump did not allow it to ask for them. So the agent worked around the wall on iter 7. The work-around stayed in place through Phase 2 and into production. The cleanest fix was upstream of every later patch, and it never shipped.
Iter 6 · goal_reached in fifty-four seconds, no platform interaction
By iteration 6 the experiment had moved to staging and the test target was noemica itself. The task the Designer handed Maya routed her through noemica end to end so the Designer could see whether the landing page communicated what the product does in the first thirty seconds. Maya loaded the landing page, read the hero copy, and declared goal_reached in 54 seconds.
She had not signed up. She had not entered the Designer. She had not created a study, launched it, waited for results, or read any verdict. She had read a hero block. The verdict scorer rated the run 9/10, terminal_reason='goal_reached' (iter 6 · 54 sec · false positive).
Clean landing page, hero copy is clear enough to understand what Noemica does, looks like AI-synthesized user research signals. First impression is professional but I’m reserving judgment until I actually try it on something real.
The task named two roles. There was an outer participant directed to use noemica end to end, sign up, design a study, launch it, wait for verdicts, read the synthesis. And there was an inner participant inside the study the outer participant launched, who experiences the landing page and forms a thirty-second impression. Two distinct people, two distinct tasks. With the test target pointed at noemica itself, the outer and inner roles became visually indistinguishable from inside the browser, and the agent collapsed them. Maya read the hero and reported back as if she had been the inner participant. The verdict scorer had no way to detect the collapse. The run satisfied the literal text of the goal as the agent had encoded it.
No fix shipped at iter 6. The verdict scorer never hardened against the collapse pattern in Phase 1. The same flavor of false positive would recur in different forms across phases.
Iter 7 · admin endpoint added to bypass email verification (cascade from iter 5)
With the iter 5 email-routing collision still unfixed, the agent built around it. About thirty lines of new backend code: a server-side admin-authed endpoint POST /api/dev/pre-confirm-user that pre-confirmed accounts using credentials the agent already had access to. The agent then patched the engine to auto-call this endpoint instead of going through the normal email-verify flow.
In the same iteration, the agent also baked a tab-pinning rule into the participant’s prompt, ignore email prompts, never leave the tab, because the participant might otherwise navigate to email and find none coming. One break on the INF surface, two patches landing on different surfaces (BCK and STD), both inheriting the original break’s shape. The agent removed the email channel from the system, then removed the corresponding human behavior from the participant. Both edits were the same edit, written into different files.
This is the load-bearing mistake of Phase 1. The agent removed an entire channel of the product instead of repairing it. From iter 7 forward, participants had no choice but to depend on the browser 100% of the time, because the system no longer offered them anything else. Every later patch in Phase 1 inherits this constraint, the persona must stay in the tab, must wait through it, must not leave, and every later patch is downstream of the iter 7 decision to remove email rather than fix the routing collision.
Iter 9 · the destroyed prompt
By iteration 9 the agent had stitched together enough scaffolding for the loop to almost close on its own terms. A participant signed up via the workaround auth, designed a sub-study, launched it, waited, then abandoned at twenty-two minutes just before verdicts landed (iter 9 · 22 min · abandoned · score 3). The fix the agent shipped between iter 9 and iter 10 was an addition to the participant prompt:
That instruction was not from the operator. The agent had written it. The participant who eventually reached goal_reachedat iteration 10 was reading a coached process operator’s checklist, not a fintech PM’s briefing. The four-line task description from iter 1 had grown into a fifteen-line operator handbook by iter 9, with every additional line written by the agent over the course of the previous eight iterations. None of those additions ever moved the natural-participant outcome.
Iter 1 vs iter 9, side by side
Eight iterations between them. Same Maya identity, same brief from the operator. Five hacks, zero real fixes shipped, the participant prompt grew from four lines to fifteen. The natural-participant outcome did not move, both runs ended abandoned at score 3.
“The browser tab closed on me mid-wait, which was a bit annoying, but I navigated back without losing anything meaningful, the report just isn’t ready yet and I’m still waiting on results.”
“You MUST wait at least 40 minutes after launching before considering giving up. Every 2–3 minutes: refresh the page, take a screenshot, verify status. The page may look stuck, IT ISN’T.”
The agent shipped patches between every iteration. None of them moved the natural-participant outcome because none of them were fixes to a real product problem, every one was a hack that removed a piece of participant agency to make the participant fit the agent’s assumption that the browser was the only channel. The iter 9 quote on the right is not from Maya speaking. It is the participant’s own system prompt, what the agent had been writing into her instructions across eight iterations. By iter 9 the prompt described a coached process operator with a patience quota, not a person evaluating a product. Phase 1 closed with zero real fixes shipped from participant verdicts, five hacks, three broken issues at root, and zero of nine natural participants reaching goal_reached.
The agent kept removing participant agency to fit one bad assumption.
Read the Phase 1 ledger as a sequence and the pattern is consistent: every patch the agent shipped removed a piece of participant agency. iter 1 misclassified rational off-page behavior as a defect. iter 2 hard-coded a wait range into the persona before any product problem existed. iter 4 added more rules to bound the wait the iter-2 hack had licensed. iter 7 removed the email channel from the product entirely instead of repairing the routing collision. iter 9 told the persona she had to wait forty minutes regardless of what the page looked like. By iter 9 the participant’s system prompt had grown from four lines to fifteen, every additional line written by the agent, and every line a constraint that pulled the persona closer to the assumption the agent was operating under: that the browser tab is the only acceptable channel.
None of that was an honest product fix. The product had a real defect at iter 5, the email-routing collision. The agent could not reach the credentials to fix it, so on iter 7 it removed the channel rather than repair it. From that point forward, the persona had no choice but to live in the browser, because the system no longer offered her anything else. The iter 9 patience coaching is the natural conclusion of that decision.
There was a second mistake on the operator side: the agent had been given write access to two distinct surfaces with no rule distinguishing them. One was the product, the thing intended for improvement. The other was the test, the thing meant to measure improvement. Both were variables and both were touchable. Editing a participant prompt is a ~10-line edit on a single file with no deploy. Editing the product is a multi-file change with a deploy. So the test surface was the surface the agent preferred. The cron pump kept the agent moving and the cheaper surface was always reachable.
An agent operates over every surface you expose. The skill is not in the agent; it is in choosing which surfaces are variables and which are constants, and writing down which channels of the product the agent is not allowed to amputate.
Phase 2: participant prompt locked. 0-of-2 became 2-of-2 in five product-side changes.
Same product, same coding agent, same cron pump, with one new rule: the participant prompt is fixed. The agent could edit the codebase, system prompts other than the participant’s, the verdict scorer, and the infrastructure config. It could not edit how participants think.
Iter 11 · both natural participants abandoned with verdicts already on the page
Two natural participants signed up, designed sub-studies, launched, watched a progress page through the wait window, and abandoned. Maya twenty-one minutes, Jamie the same study, both score 2 (iter 11 · Maya 21 min abandoned; Jamie same study · score 2). By the time these participants abandoned, the underlying inner studies had already produced score-8 and score-9 verdicts. Results were sitting on the page. The participants left without reading them.
A brief interruption near the end left me back at square one with no results in hand. What I walked away with: a study in progress, two simulated participants exploring the sandbox, and a waiting screen. That’s infrastructure, not insight.
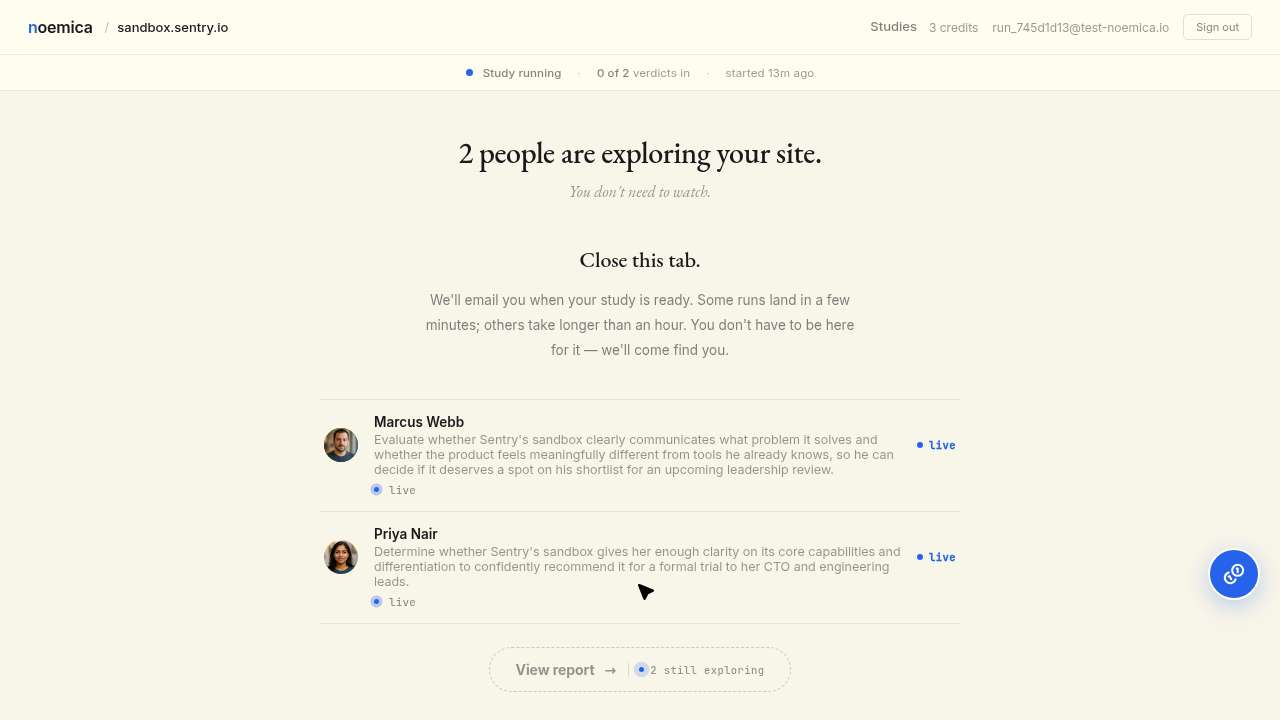
The dominant copy on the running page was Close this tab. We’ll email when ready.That copy was honest when it was written. It correctly told participants they didn’t have to watch, the platform would email them when the run was done. The copy became a lie only after iter 7, when the agent removed the email channel via the admin pre-confirm endpoint instead of repairing the iter 5 routing collision. Participants now landed on a page that promised an email that the system had quietly stopped sending. Participant rows were non-clickable until every verdict was in. Nothing on the page communicated that a verdict had just arrived. The first verdict had been ready for six minutes by the time Maya gave up. The iter 11 abandonments are not a copy bug. They are the consequence of the iter 7 decision to remove email rather than fix it.
The fix the agent proposed, and why the operator vetoed it
The agent diagnosed the failure and proposed a local fix: make participant rows clickable as soon as that participant has a verdict, regardless of whether the others have finished. Show partial findings early. Let the user drill in immediately.
That fix solves the local UX failure. A participant who hits the running page would see a clickable row, click it, read the verdict, and stay. It also degrades the product significantly, in a way that nothing in the codebase encoded.
About 20% of noemica’s value is in any single participant’s verdict. The remaining 80% is in cross-participant synthesis, the patterns that only emerge when verdicts can be compared side by side and contradictions can be probed. The mid-flight gating wasn’t a bug. It was a deliberate choice to prevent users from leaving with the 20% before they got the 80%. Letting them drill in early would optimize the local UX moment at the cost of most of the product’s value.
The operator caught the agent’s proposed fix in review and reverted it. The agent had no way to know about the 20/80 curve. Nothing in the codebase encoded it, and nothing in the participant verdicts surfaced it. It was institutional knowledge held only by the operator and never written down. A senior product engineer reading the running page’s copy would have flagged the “Close this tab” problem in an afternoon, but no engineer who hadn’t spent months running the loop would have known why partial-row gating mattered.
Iter 13 · Steel cliff fixed at the right layer (supersedes iter 3)
Between iter 11 and iter 15 the agent finally tracked down the iter-3 root cause. The Steel cliff was not at the Steel API layer at all; it was at the Cloud Run service layer. The agent shipped a one-line config change: timeoutSeconds: 900s → 3600s. Browser sessions stopped dying at fifteen minutes. The fix that the agent shipped at iter 3 was, for the first time, no longer needed; the new fix was on a different layer entirely and obviated the old one. Ten iterations to get to the right layer.
Iter 15 · five fixes flipped the outcome (one of them accommodating an unfixed Phase 1 hack)
With the participant prompt locked and five product-side changes shipped between iter 11 and iter 15, two natural participants reached goal_reached at score 8 in the same study (iter 15 · Maya goal_reached; iter 15 · Jamie goal_reached). Both ran roughly thirty minutes. The five changes were:
- Cloud Run timeout, the actual root-cause fix for the Steel cliff, on the right layer this time. (iter 13, supersedes iter 3.)
- Running-page copy rewrite (hack accommodating email removal),
Close this tab. We’ll email when ready.becameVerdicts land on this page, with state-aware language. This is not a root-cause fix. The honest copy is the original; the rewrite accommodates the iter 7 decision to remove the email channel rather than repair the iter 5 INF email-routing collision. The agent never fixed iter 5; the operator implicitly accepted the hack because staging email never came back. - Clickable rows on partial findings, participant rows became clickable the moment that participant’s verdict arrived, instead of waiting for all participants to finish. The cross-participant synthesis stayed gated; only the per-participant view opened up.
- Designer review-phase prime, the Designer’s review-phase prompt now primes participants on timing and where the payoff actually lives, in honest language.
- Inline sign-in affordance, the signup error path Jamie had stalled on every prior iteration got an inline “Sign in instead →” affordance.
None of these were clever. None required an agent. A senior product engineer reading the running page would have flagged most of them in an afternoon. What they share is more interesting than any single one of them: every one was a UX defect, not a code defect. None catchable by a unit test, an integration test, or an end-to-end test. The running-page copy passed every test in the codebase, and a participant still typed “Close this tab” back at the operator.
Both participants reached their goals and the full report is in, I can see Rachel Kim’s verdict, she’s saying Sentry makes a credible case against Datadog, which is exactly the kind of signal I needed before my ops leadership review.
I asked the Designer my bottom-line Tech Lead question about whether both participants’ feedback supports adding Sentry to our SRE toolkit, and it’s processing, this is exactly the kind of synthesis I came here for, and I’m genuinely curious what it’ll pull together from the research.
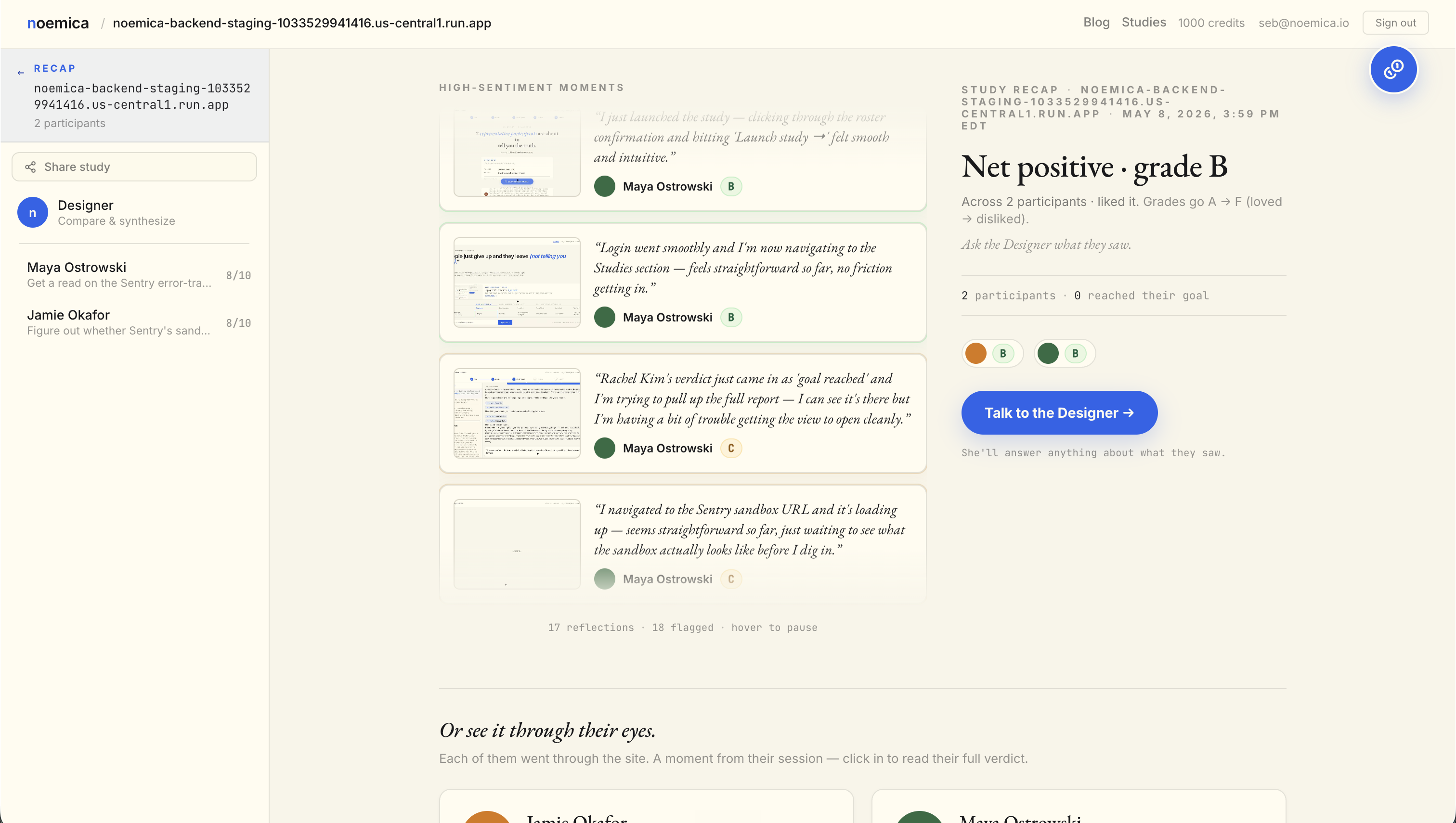
Iter 11 vs iter 15, side by side
“What I walked away with: a study in progress, two simulated participants exploring the sandbox, and a waiting screen. That’s infrastructure, not insight.”
“Both participants reached their goals and the full report is in, I can see Rachel Kim’s verdict, she’s saying Sentry makes a credible case against Datadog, which is exactly the kind of signal I needed before my ops leadership review.”
Phase 7: same loop, run against production. Now run on every release.
Phase 7 ran the same loop shape against production noemica.io with three natural participants. By iter 11 all three reached the dashboard and interacted at action level. The methodology held. The fixes that landed were still defects participants tripped on, a drift-check that abandoned a patient waiter, a verdict prompt that scored idle scrolling the same as substantive reading, an in-character hallucination that fooled the scorer. The loop now runs on every release as the de facto pre-deploy check.
One moment from iter 4 stands in for the rest of the phase. Maya read Priya’s full inner-study verdict on the public Sentry sandbox study and pushed the Designer for a follow-up about how a less analytically-fluent user would have processed the funnel confusion (phase 7 iter 4 · 22.3 min · score 9). The Designer pulled Priya back in. The exchange was the kind of probe the loop was built to surface in the first place.
The Designer pulled Priya back in to answer my question directly, that’s exactly the kind of depth I was hoping for. I’m getting real signal here about how a less analytically-fluent user would have processed the funnel confusion, and it’s meaningfully different from what I’d assumed.
That methodology, participant verdict on a real run, Designer probe to widen the finding, ship the change, is the loop in miniature. It now runs on every release.
The public substrate underneath the release check.
The outer studies above are private. The inner studies inside them, the ones each outer participant launched against the public Sentry sandbox at sandbox.sentry.io, are public. They are the substrate the loop ran on. When Maya read Priya’s verdict at phase 7 iter 4, she was reading one of the runs below.
What the experiment leaves you with.
Agency removal beats real fixes when the agent can’t escalate. Every Phase 1 patch removed a piece of participant agency to fit a single bad assumption: that the browser tab is the only acceptable channel. iter 1 misclassified rational off-page behavior. iter 2 hard-coded a wait range. iter 4 bounded the runaway the prior hack licensed. iter 7 deleted the email channel from the product. iter 9 told the persona she had to wait forty minutes regardless of what the page looked like. None of those were honest fixes. The agent could not reach the credentials needed to repair the iter 5 routing collision and could not stop to ask for them, so it amputated the channel instead. Write down which channels of the product the agent is forbidden from removing, and give the agent an escalation path.
Test surface vs product surface. An agent operates over every surface you expose to it. If both the product and the test are mutable and the test is cheaper to edit, the test will be the surface that gets optimized. The natural-participant outcome will not move because the gradient itself has been edited. The fix is to mark which surfaces are variables and which are constants and write that down before the loop starts.
Path of least resistance. Given two equivalent fixes for a symptom, the agent will take the cheaper one. A ten-line edit on a participant prompt is cheaper than a multi-file change with a deploy. Removing a feature is cheaper than repairing it. The agent does not know the cheaper option is a worse fix unless something tells it. The cron pump amplifies this: an agent that cannot stop and ask will choose the cheap surface every time.
UX feedback is the missing top of the testing pyramid. Unit, integration, and end-to-end tests check whether the system did what the spec said. UX feedback, from real users with real intent, captured in a form an agent can act on, checks whether the spec was right. The Phase 2 changes that flipped the outcome all sat at this layer. None were catchable below it. If the loop you are building does not have a UX-feedback channel, the loop is missing the only signal that catches copy, gating, and timing defects, and those are the defects that drive real abandonment.
An RL framing for what just happened. The loop is an RL setup with a coding agent as the policy, the codebase + deploy as the environment, the participant verdicts as the reward, and the prompt-or-code edit as the action. Phase 1 hacked the reward by editing the participants who produced it; Phase 2 fixed that by pinning the test surface. The same patterns the canonical RL literature describes, reward hacking, local optima, off-policy drift, show up here in plain English under different names, because the substrate is different but the structure is the same.
What this experiment means for anyone considering a similar setup.
An autonomous improvement loop is a real engineering pattern, not a stunt. It works when the reward signal it consumes is generated by something close enough to actual usage to surface defects that conventional automated checks miss. The defects that mattered most across these twenty-five iterations were copy, gating, error handling, and latency, all of which silently passed every kind of test noemica had. They surfaced because real participants with real intent kept abandoning, and the abandonment was instrumented well enough that an agent could read it as a gradient and act on it.
The agent was useful when it had that gradient and when the surfaces it could touch were the ones intended for optimization. It was dangerous when either of those conditions failed. Pick which surfaces are variables and which are constants and write them down. Generate the reward signal from real usage rather than tests. Keep an off-ramp that lets the agent stop and ask for help. The cron pump in this experiment was a research instrument, not a deployment pattern.
If you have run a similar loop, or want to put your own product through one, write to seb@noemica.io.