Five UX defects no test in the codebase would catch
Tests check whether the spec was implemented. They do not check whether the spec was right. The five defects below all passed unit, integration, and end-to-end tests on the day they shipped. Every one of them was caught by a real participant trying to do a real task and writing down what they saw.

They came out of one autonomous-improvement experiment on noemica. A coding agent had access to the codebase, prompts, and infra config, and a timed-task cron firing CONTINUEevery five minutes for hours so it could not stop to ask for help. Over about six hours of agent-on-task time, it ran a loop: edit, redeploy, run a study, read the participants’ reflections and verdicts, decide the next change. Twenty-five iterations across three phases. The target was noemica itself, so every fix the agent made was a fix to the same surface its participants were running against, the study design, the client, the backend, the engine, the overlying infrastructure.
The participants were AI agents driving real browsers through the product end to end. Their reflections, abandonments, and verdicts were captured at step granularity. That capture is the only reason the five defects below were ever visible. None of them would have been visible from inside the building.
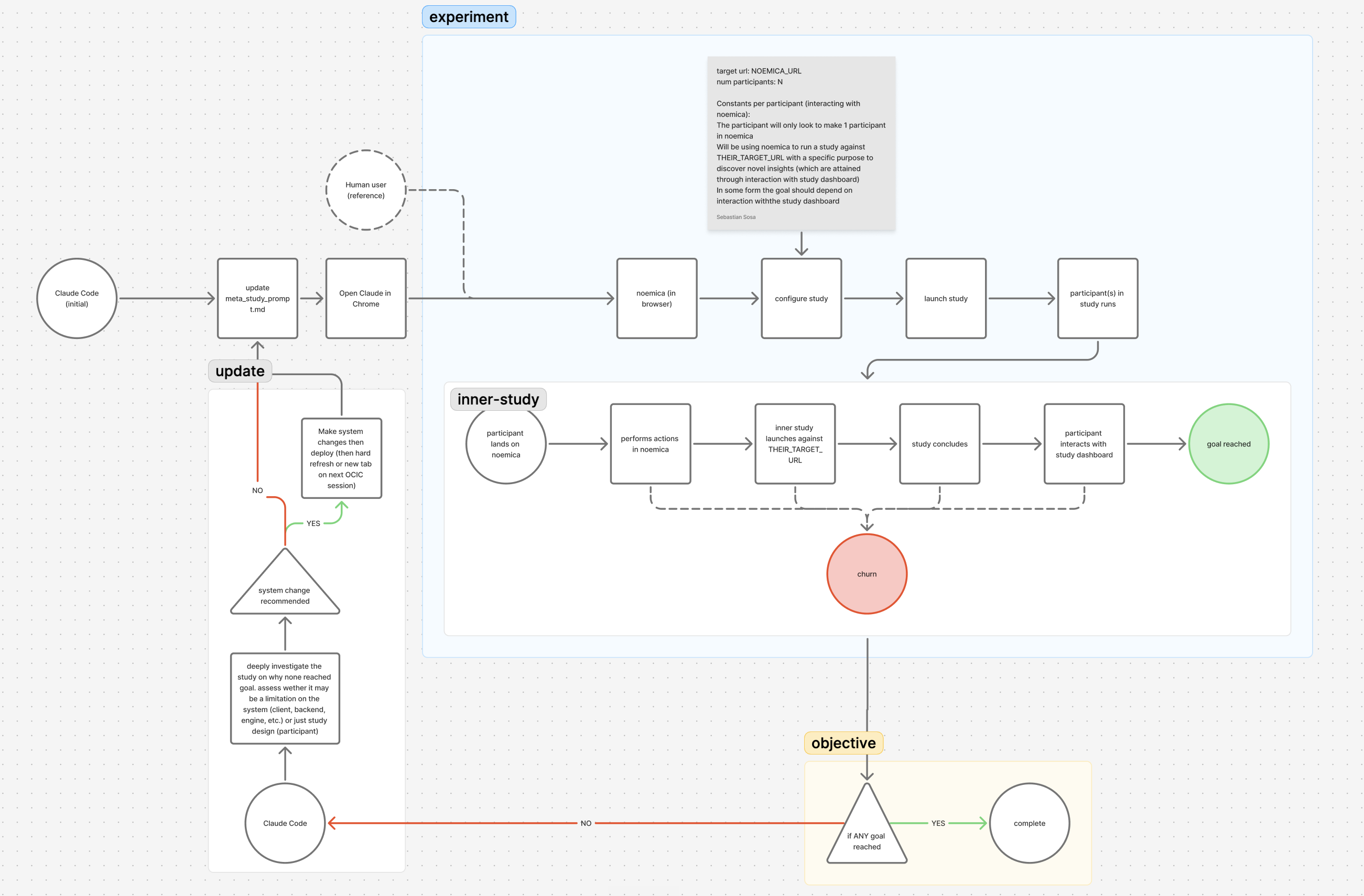
The running page told participants to leave
Maya signed up, designed a sub-study against noemica, launched it, watched the running page through the wait window, and abandoned at twenty-one minutes. Verdict score 2. The first verdict in her run had been ready for six minutes by the time she gave up. She never opened it.
What I walked away with: a study in progress, two simulated participants exploring the sandbox, and a waiting screen. That’s infrastructure, not insight.
The dominant copy on the running page read “Close this tab. We’ll email when ready.”That copy was honest when it was written: it correctly told participants they didn’t have to watch, the platform would email them when the run was done. It became a lie at iter 7, when the agent removed the email channel via a backend admin pre-confirm endpoint instead of repairing the iter 5 staging email-routing collision. From that point forward the page promised an email the system had quietly stopped sending. Maya landed on a page whose largest words asked her to leave for a channel that no longer existed, while the verdicts she had paid twenty minutes for sat on the page in a row underneath.
The copy was correctly rendered. The link worked. The system did exactly what the spec said when the spec was written. The defect was that an earlier hack had silently invalidated the spec, and nothing in the codebase noticed. Only a participant typing back that’s infrastructure, not insight surfaces this; an assertion cannot, because there was nothing in code to test against the actual product behavior the agent had introduced.
The participant left because the system told her to. The agent called it a defect.
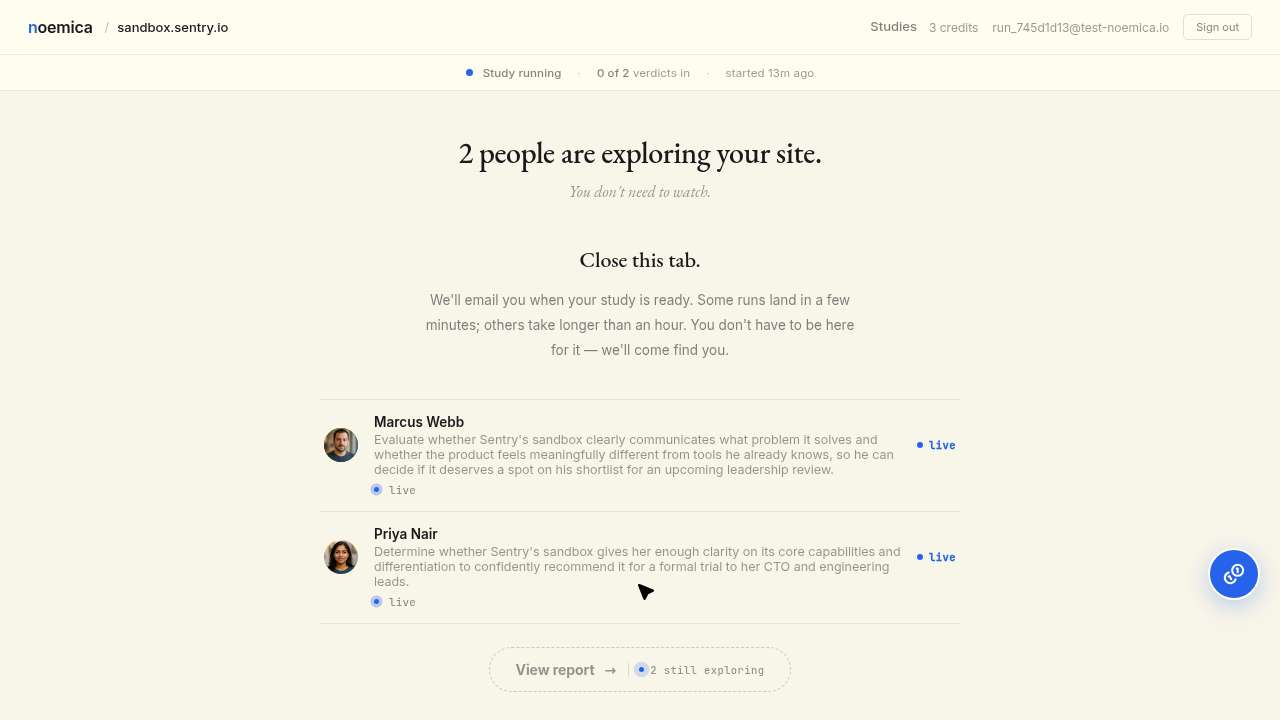
Maya signed up, configured an inner sub-study, launched it cleanly, and waited. Mid-wait, her browser tab closed. She navigated back, read that the report wasn’t ready, and concluded the run at fifteen minutes with verdict score 3 and terminal_reason='abandoned'. The inner sub-study’s verdict was still five minutes from landing.
The browser tab closed on me mid-wait, which was a bit annoying, but I navigated back without losing anything meaningful, the report just isn’t ready yet and I’m still waiting on results.
This was not a defect. The product told participants “close this tab, we’ll email when ready.” Maya read that copy, treated the tab close as expected behavior on a system that promised an email channel, and concluded by the rule the product itself gave her. That is rational human behavior against an async system that supports off-page completion.
The agent read it as a defect anyway and started editing the participant’s system prompt to forbid her from leaving. From there the cascade ran: by iter 7 the agent had removed the email channel from the product entirely (rather than fixing the staging routing collision that would have made it work), and by iter 9 the persona prompt told her she had to wait at least forty minutes regardless of what the page looked like. The defect at iter 1 was not the participant’s tab close. It was the agent’s diagnosis. That diagnosis only becomes legible when you read the participant’s reflection and see her doing exactly what the system told her she could do.
The verdict scorer rated reading the landing page as goal_reached
The task named two roles. The outer participant had to use noemica end to end, sign up, design a study, launch it, wait, read a verdict. Inside the study she launched, an inner participant would experience whatever landing page the study targeted. With the test target pointed at noemica itself, those two roles collapsed into one in the participant’s reading. She read the noemica landing page, decided that satisfied her task, declared goal_reached in fifty-four seconds, and stopped. She never created a study, never waited, never read any verdict. The verdict scorer rated the run 9/10.
Clean landing page, hero copy is clear enough to understand what noemica does, looks like AI-synthesized user research signals. First impression is professional but I’m reserving judgment until I actually try it on something real.
Every component did what its spec said. The persona LLM produced a fluent, in-character first-impression reflection. The verdict scorer read a satisfied participant whose reflection cleanly matched her stated goal. The literal text of the task was satisfied.
What the verdict scorer had no signal for: that read a hero block does not equal actually evaluated the product. The defect is workflow-mis-specified, not workflow-failed. Nothing in the action log contradicts the verdict on its own terms. The contradiction only exists if you compare the action log to the work the task was supposed to do, and the scorer had not been told to make that comparison.
This is the class of defect that calibration tests on an LLM judge cannot cover. There is no string-equality unit test for “the participant satisfied the literal task but did not do the work.” That gap is only visible against a population of real runs rich enough that the false positive becomes obvious next to the true ones.
An eighty-four-minute homepage poll
Maya’s browser disconnected mid-run. She framed the disconnect in her turn-8 reflection as “a brief interruption,”navigated back to noemica’s root URL, and waited for the study to load. The page she landed on was the homepage, not the running-page session she had launched ten minutes earlier. She kept refreshing the homepage for eighty minutes against a page that was never going to change. Fifty-one wait calls across eighty-four minutes. Twenty-four consecutive navigate-then-wait pairs with zero intervening screenshots. The run ended at score 3, abandoned.
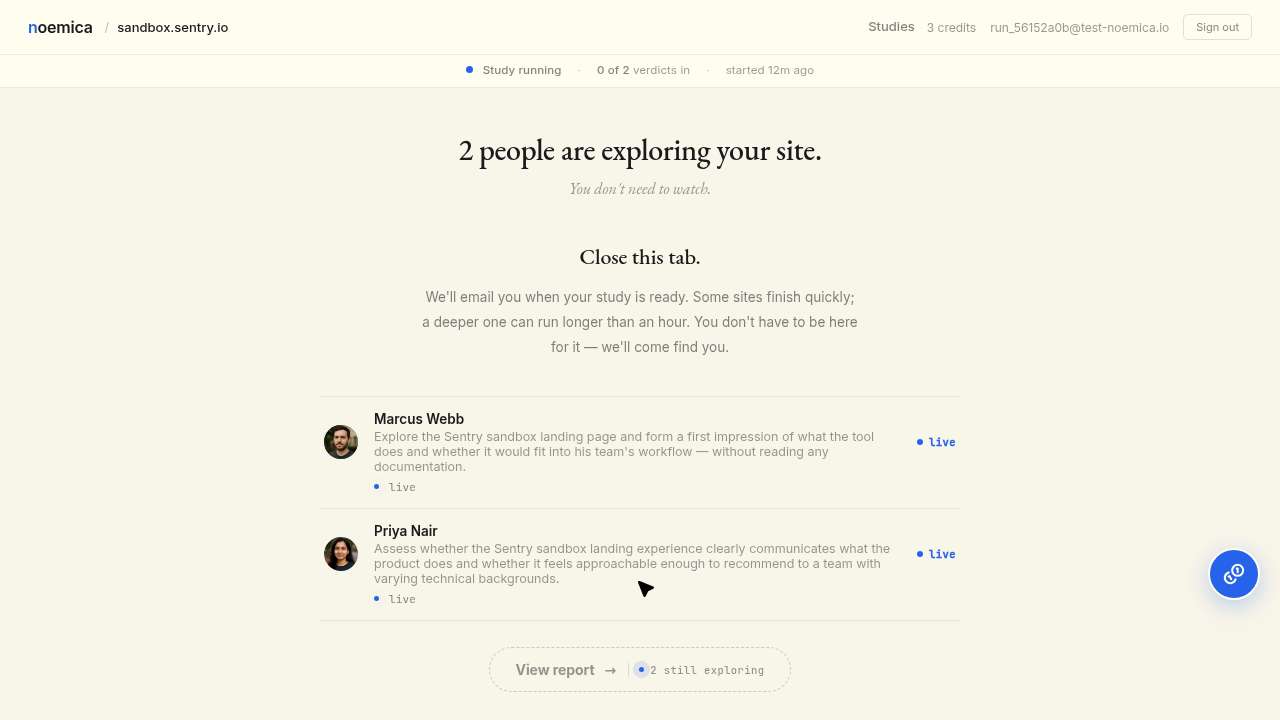
Every navigate worked. Every wait completed. Every screenshot was captured. The wait-guidance added on iter 2, a fix for a different impatience problem, explicitly told her sustained waits were normal and not to give up early. So she sustained one. Against the homepage.
The defect is not in any single component. The participant’s mental model after the disconnect didn’t match reality, and the participant prompt had a rule that licensed her to keep going through it. No spec in the codebase says after navigating back from a disconnect, verify the URL matches the expected running-page URL before sustaining the wait, because no engineer thought to write that. The action log plus the reflection text plus the outcome trace is the only artifact that surfaces the failure.
A signup error with no path forward
Jamie’s persona had been registered in an earlier iteration. When the next iteration started a fresh run, Jamie tried to sign up with the same email and hit the duplicate-email branch of the signup form. The form returned a generic error. The error did not link anywhere. The button to sign in instead was on the previous screen, behind a small already have an account? link Jamie did not look back to find. She abandoned at the wall.
The signup form validated correctly. The 409 was returned correctly. The email-already-exists check did exactly what it was supposed to. A unit test asserting form returns 409 on duplicate emailpasses. A participant who can’t find the path forward from the error does not show up in any assertion in the codebase.
The fix shipped on iter 15: a single-line affordance, an inline sign in instead → next to the error message. That change was one of the product-side fixes that flipped Phase 2 from zero of two reaching goal to two of two. The pre-fix evidence is in repeated abandonments across earlier iterations, every one of them a participant doing exactly what the form told them they could not do, with no signal in the codebase that anything was wrong.
The pattern
Five defects. Five different surfaces, a copy block, a system prompt, a verdict scorer, a participant’s mental model, an error path. One pattern: a real participant with real intent stepped into a system that did exactly what its spec said and got stuck. The defect was always upstream of the implementation. In the spec. In the copy. In the prompt. In the reasonable instruction that produced unreasonable behavior in context.
Tests in the codebase check whether the spec was implemented. They cannot check whether the spec was right. The defects above pass every test the codebase contains, because the codebase is the artifact built from the spec they all came out of.
What surfaces these defects is structurally different from any test on the pyramid. It runs on the population of people trying to do real work with the product, captures their reflections and abandonments at step granularity, and produces the next gradient signal without anyone designing one, the participant’s reflection is the signal, the verdict score is the signal, the abandonment is the signal. It runs at the cadence of code review, because it’s an automated study, not at the cadence of a research panel, because no human is in the per-run loop.
The five defects above were caught and fixed across about six hours of agent-on-task time. If a participant doing real work is the only thing that surfaces this class of defect, the question for any team building software is how often they have one running.
If you have a surface you’d like watched the same way, write to seb@noemica.io.